
Abstract
An electric vehicle (EV) centred ecosystem has not yet been formed, the existing limited statistic data are far from enough for the analysis of EV users’ travel and charge behaviors, which however tends to be affected by many certain and uncertain factors. An experimental economics (EE) based simulation method can be used to analyze the behaviors of key participants in a system. However, it is restricted by the system size, experimental site and the number of qualified human participants. Therefore, this method is hard to be adopted for the behavioral analysis of a large number of human participants. In this paper, a new method combining a questionnaire statistics and the EE-based simulation is proposed. The causal relationship is considered in the design of the questionnaires and data extraction, then a multi-agent modeling integration method is introduced in the EE-based simulation, which enables the integration of causal/statistical/behavioral models into the multi-agent framework to reflect the EV users’ travel willingness statistically. The generated multi-agents are used to replace human participants in the EE-based simulation in order to evaluate EV users’ travel demands in different scenarios, and compare the differences of simulated or measured travel behaviors between potential EV users and internal combustion engine (ICE) vehicle users.
Similar content being viewed by others


1 Introduction
The popularization of electric vehicles (EVs) is becoming an exciting part of the current energy revolution wave. It also brings considerable opportunities and challenges to various related industrial sectors, such as vehicle/battery manufacturing, traffic/power/fossil-energy industries and urban construction. For the power industry, it is very vital to achieve a friendly interaction between the power grid and EVs, which involves timely, convenient and reliable charge service provided by power grids for EVs, the sufficiency of taking into account mass roll-out of EVs in smart grid construction, the strengthening of demand side management, and the establishment of a suitable market mechanism to promote the participation of EVs in ordered charge and ancillary services [1]. All these cannot be achieved without the availability and analysis of the operation data of a large number of EVs, which however depend on the developments of EV user groups that are still in progress. This deadlock represents an obstacle of research to analyze the interactions between power grids and EVs systematically using traditional technologies.
Experimental economics (EE) [2, 3] is a powerful tool for mechanism research and decision optimization, which considers the influences of human subjective willingness and gaming behaviors that are however absent in the traditional research in the economy and social science. An EE-based simulation method can be used to analyze the behaviors of key participants in complex systems [4,5,6]. On one hand, this method requires a complete dynamic model of a complex system, on the other hand, it is limited by the system size, experiment site, the number of qualified human participants and research time. The sensitivity analysis is often used to assess the significance of the contribution of one parameter to the result and critical to find out the optimal optimization direction, and this is achieved by keeping other parameters unchanged while only one parameter is regulated. An EE-based method has an intrinsic deficiency, i.e. human participants have to keep their decisions unchanged while the target parameter is varied in repeated experiments in order to investigate its contribution, which is however often infeasible.
A survey questionnaire method is also a kind of EE-based or experimental sociological research approach. To conduct EE-based study of the EVs’ purchase willingness, the questionnaire-based method is used to overcome the limitation of the simulation-based method. Based on the joint probability density distribution of decision-making options for multiple contributing factors, a multi-agent model is established to reflect the purchase willingness of potential EV users [7].
To research users’ travel behaviors, the available data of users of internal combustion engine (ICE) vehicles, such as travel time, departure point, destination, etc., are abundant [8,9,10]. Existing statistical researches on EV users’ travel and charge behaviors are often based on these data [11,12,13]. However, it should be pointed out that the available data from ICE vehicle users may not be suitable for EV studies, and a careful distinction should be made. The researches on users’ range anxiety concluded that EV users pay more attention to the travel plans than owners of ICE vehicles [14, 15]. It is therefore necessary to combine selected behavior data of ICE vehicle users with the travel willingness of EV users.
Different from the study of the purchase willingness of potential EV users, EV users have to face much more specific travel scenarios. The causal relations among the features that affect users’ travel decisions are much stronger, and they are highly correlated. For example, the estimation of charge times during a trip depends on the range and users’ range anxiety. Existing causal analysis methods are based on deterministic models based on users’ behaviors in typical scenarios, however, the uncertain behaviors of different user groups in different scenarios cannot be represented [16,17,18]. And on the other side, statistical analysis methods provides no joint probability distribution functions of high-dimensional random variables extracted from questionnaires and statistical data [19]. In order to solve these problems, it is essential to introduce causal analysis in questionnaire design and data mining.
Given the above considerations, and on the basis of big data thinking [20, 21], our previous work on EV’s purchase willingness [7] and travel willingness [22] are first reviewed. Then an integrated multi-agent model is proposed, which is based on the two-step information extraction of joint probability density distribution in order to reflect EV users’ travel willingness. Furthermore, verification and error analysis of multi-agent simulation results are conducted. Finally, based on the simulation of the EV users’ travel willingness using the proposed multi-agent model, the difference of simulated or measured travel behaviors between the potential EV users and ICE vehicle users is analyzed in detail.
2 Multi-agent based integration of multi-source heterogeneous data
2.1 Descriptions of multi-source heterogeneous data
Multi-source heterogeneous data include causal data, statistical data, and the behavioral data of human participants [20]. Causal data are often derived from mathematical models that represent causal relationships among events. Statistical data on the other hand contain no casual relationships among deterministic events. The statistical correlation among events therefore has no causal relations, rather than a kind of coincidences. It should be noted that events with causal relations may not be correlated statistically. The nature of statistical data is a presentation of full-dimensional and unlimited data in a limited and compressed set of dimensions. Behavioral data are the outputs of humans’ decision-making process under a limited dimensional data. Most behavioral data are records of human gaming behaviors in real markets, such as GPS data used to track people’s movement, and transactional data for tracking the financial behaviors.
2.2 Multi-agent based integration method
Based on the above discussions, Fig. 1 describes a multi-agent integration method to deal with multi-source heterogeneous data. The multi-agent model is used as an interface to communicate with the integrated simulation model of human behaviors, fitting causal/behavioral/statistical data with a hybrid simulation environment. Considering the lack of qualified and professional human participants, this simulation environment is an effective tool to transform the traditional decision-making process into a computer-aided approach through a sand-box-like simulation and optimization. Generating qualified multi-agents to replicate the decision-marking outputs of the human participants is the key technology to achieve this method.

Block diagram of the multi-agent integration method to deal with multi-source heterogeneous data
Multi-agents are usually generated from optimization models by using expert knowledge and intelligent learning methods [23]. If the multi-agents are only demanded to imitate the behaviors of participants, they can be directly generated from one or more types of sources in the behavioral/statistical/causal data. As an example, the multi-agent model has been generated from behavioral data in [24, 25]. However, it is not easy to obtain behavioral data from near-reality scenarios because the process will cost a lot of qualified human participants a large amount of time. In order to solve this problem, [7] has tried to generate the multi-agents from statistical data. In this paper, causal and statistical data are both used to handle more complicated modeling problems. The relations of the above models are shown in Fig. 1.
The data collected from the traditional questionnaires is a kind of statistical data. Typical data mining on the questionnaire data is to identify the relationship between the threshold of a single feature and the decision results using a statistical method. However, users’ decisions are often influenced by multiple features. The statistical results focusing on a single feature ignore the contribution of other features. Merely depending on the statistical methods, to reveal the correlations between decisions and multi-dimensional data may require a significant amount of data. On the contrary, causal analysis is a data saving approach. Therefore, combing the causal and statistical analysis represents an effective approach to achieve high-quality data mining based on a reduced size of data. In order to obtain causal data, causal analysis is done at the design stage of the questionnaire.
3 Data extraction and multi-agent modeling
3.1 Feature extraction
Due to the short range and unavailability of fast and efficient charge facilities, the features influencing EV users’ travel behaviors are far different from ICE vehicles. These features include “vehicle performance”, “user anxiety” and “travel pre-estimate”. In this paper, the range is thought as a key feature in “vehicle performance”; range anxiety, time for quick charge and queuing up during a trip, etc., are chosen to reflect “user anxiety”; user’s travel choice when facing different charge lengths during a trip is chosen to describe the influences of “travel pre-estimate”.
3.2 Questionnaire design based on causal analysis of features’ relationship
The questionnaire designed for EV users’ travel willingness faces the challenges of the variety of travel scenarios. However, a successful design cannot be only built on an exhaustive testing of all uncountable scenarios, but on a largely compressed number of questions. Significant influence are noticed among the features of “range” (“a” in Table 1), “range anxiety” (“b” in Table 1) and “travel pre-estimate” (“e”, “f”, “g” in Table 1). The first step to design the questionnaire is to deconstruct these relations. In order to know the number of charge times for a given travel scenario, users’ choices on “range” and “range anxiety” should be known first, which are set to the pre-requisites of “travel pre-estimate”. In the answers of the questions about “travel pre-estimate” features, the degree of “depending on other conditions” is designed to be related to the “user anxiety” features (“c”, “d” in Table 1), in order to decrease the similarity among questions, avoiding respondents’ boredom. Meanwhile, a question to sort the importance of “user anxiety” features (“c” in Table 1) is designed for multi-agent modeling.
Through the introduction of different psychological thresholds for the three types of features discussed above, questions in the survey have been designed and listed in Table 1.
3.3 Two-step extraction of deep information
According to Table 1, a questionnaire survey was conducted mainly among Chinese young people aged between 25 and 35. A total of 200 effective questionnaires were collected. Each answer sheet includes a deterministic opinion about all the features. An agent is generated from the high-dimensional joint probability distribution extracted from the answer sheets by Monte-Carlo random sampling so that the colony of multi-agents has the same output distribution as the respondents’ colony. Figure 2 illustrates the two-step process to extract information (causal and statistical data) in regards to the EV travel willingness, where P(ci.j) represents the probability distribution of the ith (i = 1, 2) important feature when rule j (j = 1, 2) is used; P(di.j) represents the probability distribution of psychological thresholds of the ith (i = 1, 2, 3) important feature when rule j (j = 1, 2) is used. The rules include: ① Rule 1—If the number of samples is sufficient, the distribution counting is strictly conducted on the corresponding data from questionnaires; ② Rule 2—If the number of samples is insufficient, the correlation between features is ignored and the independent distribution of the corresponding feature is used directly. The key parts include the extraction of conditional probabilistic distributions from “travel pre-estimate” questions, the probabilistic distributions from importance sorting questions for “user anxiety” features and the probabilistic distributions of features’ psychological thresholds for “user anxiety” questions. The joint probability distribution of causally related features (“a”, “b”, “e”, “f”, “g” in Table 1) is extracted in Step 1. Then the features whose relations are more statistical are processed in Step 2. The probability distribution of “user anxiety” features (“d” in Table 1) is also extracted by their order of importance in Step 2.

Flow chart for extracting deep information by two steps from questionnaires
In Step 1, the probability distribution of “travel pre-estimate” is calculated with conditional probability due to causal relations among “range”, “range anxiety” and “travel pre-estimate”. Figure 3 shows the respondent’s distributed proportion considering “range” and user’s “range anxiety” at the same time, called the conditional probability distribution of “range anxiety” P(b|a), each color represents a corresponding degree of “range anxiety”. The results also reveal that the respondent’s common choices of “range” are located within 160-480 km (85% in total). The majority of every group always chooses medium “range anxiety”. Groups giving the extreme choices of “range” (the value is ≤ 80 km or ≥ 640 km) prefer to choose extreme “range anxiety”.

Conditional probability distribution of “range anxiety”
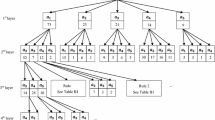
When extracting probabilistic distribution of “user anxiety” features in Step 2, the design of importance sorting question will help decide the order of features to be extracted, and also help avoid information loss caused by insufficient number of samples by using suitable approximation rules [7]. In order to store joint probabilistic data effectively, Fig. 4 shows a tree-like correlation data structure among adjacent layers for sorting feature importance, where mk (k = 1, 2, 3) represents these three features respectively, namely “time for quick charge and queuing up during a trip”, “walking distance between long-time stay point to the nearest charge station” and “chance to change travel plans by some uncertain factors”. Each branch node of the “tree” reflects the “frequency” (the number of choosers) distribution of each feature. Since there is no uncertainty associated in the final layer, the “tree” contains two layers to present the correlation among three features. After the sorting is done, the joint probability distribution of “user anxiety” features can be built layer by layer according to the layer parsing sequence determined by the importance sorting information.

Tree-like data structure storing respondents’ choosing frequencies in order to determine layer parsing sequence for “user anxiety” features
4 Generation and verification of the integrated multi-agents
4.1 Generation of multi-agents
Figure 5 illustrates the algorithm to generate multi-agents reflecting EV users’ travel willingness. The first half of Fig. 5 summarizes the procedure to extract multi-dimensional correlation information in Section 3. The second half of Fig. 5 models multi-agents by using the Monte-Carlo stochastic sampling method based on the multi-dimensional probabilistic distributions generated in Section 3. Each agent model represents a simulated individual. The final target is to obtain an agent colony that mimics the response of the corresponding colony of respondents (potential EV users) to different scenarios on travel willingness.

Flow chart to generate individual agents to reflect EV user’s travel willingness
4.2 Verification of the multi-agent model
The benchmark is the ratio of the respondents who give up using EVs in a given travel scenario, calculated by the judgment of each respondent’s willingness based on his or her answer sheet. The ratio to be compared is the proportion of simulated agent individuals (around 100000 individuals in total), created by the multi-agent model mentioned in Fig. 5, who “decide” to give up using EVs under the same travel scenarios. The effectiveness of the multi-agent model can be evaluated based on the difference between the simulation result (the latter) and the benchmark result (the former).
Figure 6 shows the relation between the ratio of traveler negative to use EVs and travel distance (step by 10 km). A specific travel scenario is used as an example. Obviously, the curves of benchmark result and the simulation result highly coincide with one another. By setting the threshold value of other features to the lowest or highest level, the upper or lower boundaries of the ratio of traveler negative to use EVs can be obtained, illustrated as the green solid lines in Fig. 6.

Comparison between the agent-based simulation and benchmark results under the scenarios with different travel distances
Figure 7 reveals the average errors between multi-agent simulation results and the benchmark results under different travel scenario sets, where sk (k = 1, 2, 3, 4) represents these 4 parameters respectively, namely “travel distance (km)”, “time for quick charge (min)”, “time for queuing up during a trip (min)”, and “time for walking from long-time stay point to the nearest charge station (min)”. Each scenario set contains scenarios randomly generated from a basic scenario by regulating values of 2 selected features. Different scenario set has different combination of feature selection. Figure 7 indicates that the average error remains below 3%. Therefore, the effectiveness of the multi-agent model, as well as the accuracy of multi-agent simulation, is guaranteed.

Errors between multi-agent simulation results and the benchmark results under testing travel scenario sets
5 Application of the multi-agent model
By using the verified travel willingness model of potential EV users, the EV-related system can be studied quantitatively.
5.1 Data cleaning of ICE vehicle data
Due to the differences between EVs and ICE vehicles, on issues like range and fuel recharge, etc., it is necessary to cleanse the travel data of ICE vehicle users.
The multi-agent model developed in Section 4 is used to filter the travel data of ICE vehicle users, and evaluate their potential charge demands. Figure 8 gives the flow chart of this data cleansing process. Firstly, an agent created from the multi-agent model is informed of the travel scenarios of ICE vehicle users, and “decides” its maximum acceptable daily travel distance “DEV”; then the daily travel data of ICE vehicles is used to create the agent’s travel need described by the daily travel distance “D”; finally, the agent’s choice whether to use EVs or not is determined by comparing “DEV” with “D”.

Flow chart of filtering ICE vehicle users’ travel surveys by using multi-agent simulation results which reflect EV users’ travel willingness
Ignoring the influence from “time for quick charge and queuing up” and “walking time from long-time stay point to the nearest charge station”, as well as “uncertain factors”, the maximum acceptable daily travel distances of an agent is willing to use EV is represented as the blue curve in Fig. 9. Based on the curve, the users who are willing to use EVs are filtered out according to the probability distribution of ICE vehicle daily travel distance (the green curve in Fig. 9) from the U.S. national household travel survey (NHTS) [26]. The red curve in Fig. 9 shows the simulated travel distance of EV potential users considering multiple features.

Probability distribution of daily travel distance and probability density of the acceptable maximum daily travel distance
5.2 Simulation analysis of EV charge behaviors
The NHTS data also gives the start time of users’ first trip and the end time of users’ last trip in a day, which is shown in Fig. 10. They both follow the normal distribution. In addition to the daily travel distance information in section 5.1, EVs’ daily charge demands can be estimated.

Distribution of travel time
The simulation of the EV charge behaviors includes 100000 agents who have travel willingness on EVs, supposing every EV consumes energy of 15 kWh per 100 km averagely, and will charge to 100% state of charge (SOC) after the last daily trip with no delay. Figure 11 shows EVs’ daily charge load levels on different charge power. The results indicate that, the higher the charge power is, the higher the charge peak-load is. Lower charge power tends to cause more obvious load superposition effect. Delaying charge is an effective way to decrease the load peak.

Simulation results of EVs’ charge load with different charge power
6 Conclusion
In this paper, an integrated causal/statistical/behavioral multi-agent model is established to simulate EV users’ travel willingness, in order to incorporate the causal relations among different features, which influence EV users’ travel willingness into the typical questionnaire-based statistical analysis. Questions are designed to cover three features, including “vehicle performance”, “user anxiety” and “travel pre-estimate”, and parsed in the sequence determined by the causal relations among these features. The joint probability distribution of respondents’ choices considering these strongly correlated features is extracted, and the multi-agent model which reflects EV users’ travel willingness is built. The comparative study of the travel willingness results between the multi-agents and the respondents confirms that the multi-agent model is a good approximation of the respondents group in presenting travel willingness. This model is used in cleansing the travel data of ICE vehicles from NHTS, through filtering unfitted EV travel modes. Based on these data, the influences of EVs’ uncontrolled charge on the load curve are analyzed.
The study of EV users’ travel willingness is a typical case to model human behaviors based on multiple contributing features that are causally correlated, which is widespread. The exploration of combining causal/statistical/behavioral analysis in a multi-agent framework may provide an effective framework to explore an entirely new solution.
References
Yu XH, Xue YS (2016) Smart grids: a cyber-physical systems perspective. Proc IEEE 104(5):1–13
Samuelson L (2005) Economic theory and experimental economics. J Econ Lit 43(1):65–107
Guevara-Cedeño JY, Palma-Behnke R, Uribe R (2012) Experimental economics for teaching the functioning of electricity markets. IEEE Trans Educ 55(4):466–473
Huang J, Xue YS, Xu JB et al (2011) Dynamic simulation platform for power market and power system part one function design. Autom Electr Power Syst 35(10):16–23
Xie DL, Xue YS, Xue F et al (2011) Dynamic simulation platform for power market and power system part two support layer design. Autom Electr Power Syst 35(11):1–7
Xie DL, Xue YS, Xue F et al (2011) Dynamic simulation platform for power market and power system part three application layer design. Autom Electr Power Syst 35(12):7–14
Xue YS, Wu JA, Xie DL et al (2015) Multi-agents modelling of EV purchase willingness based on questionnaires. J Mod Power Syst Clean Energy 3(2):149–159
Collia DV, Sharp J, Giesbrecht L (2003) The 2001 National Household Travel Survey: a look into the travel patterns of older Americans. J Saf Res 34(4):461–470
National Household Travel Survey (2001) Available from: http://nhts.ornl.gov/2001/usersguide/UsersGuide.pdf
Krumm J (2012) How people use their vehicles: statistics from the 2009 National Household Travel Survey. In: SAE 2012 world congress and exhibition, Detroit, United States, 24–26 April 2012. https://doi.org/10.4271/2012-01-0489. https://www.microsoft.com/en-us/research/wp-content/uploads/2016/12/2012-01-0489-SAE-published.pdf
Liu ZX, Wu QW, Christensen L et al (2015) Driving pattern analysis of Nordic region based on National Travel Surveys for electric vehicle integration. J Mod Power Syst Clean Energy 3(2):180–189
Soares J, Borges N, Canizes B et al (2015) Probabilistic estimation of the state of electric vehicles for smart grid applications in big data context. In: Proceedings of the IEEE PES General Meeting, Denver, USA, 26–30 July 2015, pp 1–5
Yao WF, Zhao JH, Wen FS et al (2013) A hierarchical decomposition approach for coordinated dispatch of plug-in electric vehicles. IEEE Trans Power Syst 28(3):2768–2778
Bunce L, Harris M, Burgess M (2014) Charge up then charge out? Drivers’ perceptions and experiences of electric vehicles in UK. Transp Res Part A Policy Pract 59:278–287
Shaw S, Bunce L, Kottász R (2014) Report to inform the setting up of regional e-mobility information centres. London, United Kingdom, 11th April 2014. http://e-mobility-nsr.eu/fileadmin/user_upload/NEWS/New_report__Recommendations_for_setting_up/E-mobility6.8_FinalSS-2-13.06.14.pdf
Li G, Zhang XP (2012) Modeling of plug-in hybrid electric vehicle charging demand in probabilistic power flow calculations. IEEE Trans Smart Grid 3(1):492–499
Ashtari A, Bibeay E, Shahidinejad S et al (2012) PEV charging profile prediction and analysis based on vehicle usage data. IEEE Trans Smart Grid 3(1):341–350
Ban MF, Yu JL (2015) Procedural simulation method for aggregating charging load model of private electric vehicle cluster. J Mod Power Syst Clean Energy 3(2):170–179
Chen CF, Xu XJ, Frey S (2016) Who wants solar water heaters and alternative fuel vehicles? Assessing social-psychological predictors of adoption intention and policy support in China. Energy Res Soc Sci 15:1–11
Xue YS, Lai YN (2016) Integration of macro energy thinking and big data thinking part one big data and power big data. Autom Electr Power Syst 40(1):1–8
Xue YS, Lai YN (2016) Integration of macro energy thinking and big data thinking part two applications and explorations. Autom Electr Power Syst 40(8):1–13
Wu JA, Xue YS, Xie DL et al (2015) Questionnaire designing, multi-agent modeling and analyzing of EV users’ traveling willingness. In: Proceedings of 10th international conference on advances in power system control, operation and management (APSCOM 2015), Hong Kong, China, 8–12 November 2015, pp 129–134
Vandael S, Claessens B, Ernst D et al (2015) Reinforcement learning of heuristic EV fleet charging in a day-ahead electricity market. IEEE Trans Smart Grid 6(4):1795–1805
Huang J, Xue YS, Jiang C et al (2015) An experimental study on emission trading behaviors of generation companies. IEEE Trans Power Syst 30(2):1076–1083
Jiang C, Xue YS, Huang J et al (2014) Modeling multi-agent in carbon emission market based on experimental economics simulations. Autom Electr Power Syst 38(17):80–86
Tian LT, Shi SL, Jia Z (2010) A statistical model for charging power demand of electric vehicles. Power Syst Technol 34(11):126–130
Acknowledgments
This work is supported by National Natural Science Foundation of China (No. 51407039), and State Grid Corporation Project “Analysis and function designs of correlations between the power system and its external information”.
Author information
Authors and Affiliations
Corresponding author
Additional information
CrossCheck date: 27 February 2018
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
WU, J., XUE, Y., XIE, D. et al. Multi-agent modeling and analysis of EV users’ travel willingness based on an integrated causal/statistical/behavioral model. J. Mod. Power Syst. Clean Energy 6, 1255–1263 (2018). https://doi.org/10.1007/s40565-018-0408-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40565-018-0408-2